

Jerry
2019年6月22日
890
首先说一下大体的流程,简单的流程图如下:
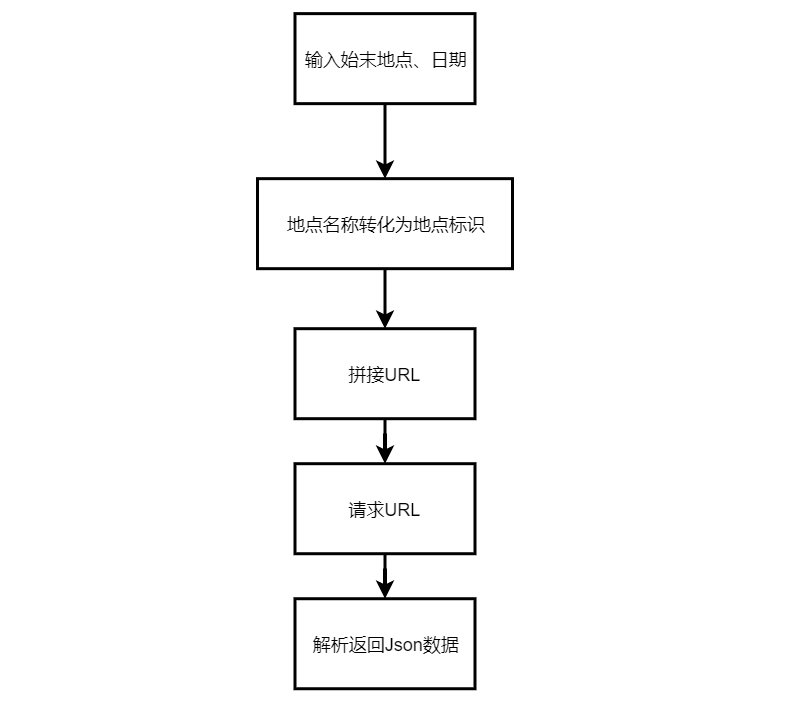
1、获取URL
打开12306余票查询的 网页链接,浏览器(我用的chrome)按F12来分析请求。输入要查询的起始地点和时间后点击查询,可以看到右侧抓到的链接信息:
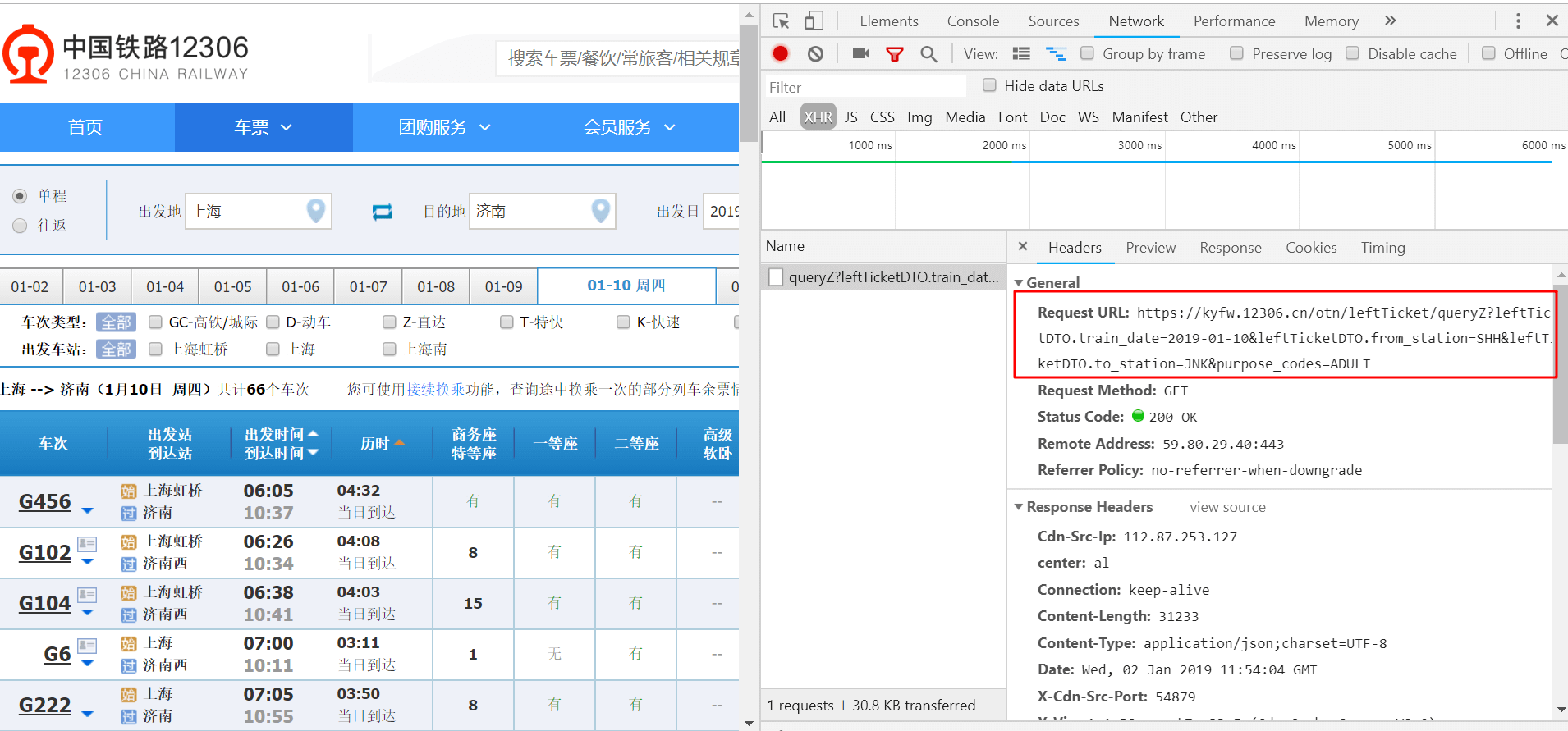
这个Request URL 便是我们需要的请求链接: Request URL:
大体有以下四部分组成:
(1)train_date:发车时间,注意格式是“yyyy-mm-dd”
(2)from_station:出发站点标识
(3)to_station:到达站点标识
(4)purpose_code:购票类型,有成人(ADULT)、学生(0X00)等。
2、获取站点标识
出发站和到达站是用字母简写标识的,我们需要找到他们的对应关系。网页源代码搜索“station_version”可以找到如下一个链接,打开后可以看到,里面保存的就是这站点名称和字母缩写的对应关系。


格式为:"xxx|汉语名称|代码标识|yyy "。我们需要做的就是将这些信息保存到字典中备用,进行对名称进行转化。
以上两部分的代码如下:
import re
import requests
STATION_DICT_URL = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9088'
def getStation(sta):
str = requests.get(STATION_DICT_URL).text
#匹配中文的正则表达式
area = re.findall("([\u4E00-\u9FA5]+)\|([A-Z]+)",str)
area = dict(area)
if sta in area:
return area[sta]
'''
url = 'https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-10&leftTicketDTO.from_station=SZH&leftTicketDTO.to_station=WFK&purpose_codes=ADULT
'''
def getUrl(from_sta, to_sta, date):
url = 'https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=' + date + '&leftTicketDTO.from_station=' + from_sta + '&leftTicketDTO.to_station=' + to_sta + '&purpose_codes=ADULT'
return url
3、分析返回结果
拼装出上述链接后直接request.get即可获得回应数据:
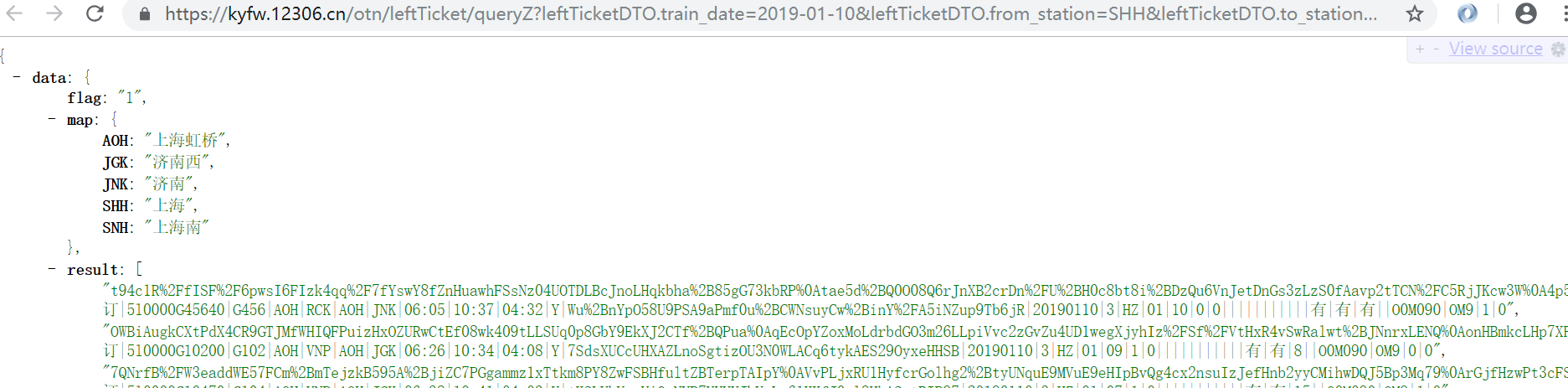
我这里用了一个谷歌浏览器的Jsonview插件,下载地址,可以比较直观的展现Json数据。对返回的Json数据仔细比较分析就可以得到对应关系。
map存储的是查询到结果相关的站点标识,result里面保存的是余票信息、时间信息等。主函数如下:
if __name__ == '__main__':
arguments = docopt(__doc__, version='TicketsQuery v1.0')
from_sta = arguments.get("<from_sta>")
to_sta = arguments.get("<to_sta>")
date = arguments.get("<date>")
#将汉字转换为特定编码
from_sta_code = getStation(from_sta)
to_sta_code = getStation(to_sta)
#拼接url 用来get
url = getUrl(from_sta_code, to_sta_code, date)
print(url)
#请求url
html = requests.get(url)
html.encoding = 'utf-8'
print(html.text)
#网页返回200 Ok进行解析
if html.status_code == 200:
#获取json
try:
res = html.json()["data"]["result"]
#print(res)
sta_dict = html.json()["data"]["map"] #获得到一个字典 用于站点的汉字和字符标记转换
#做表
table=PrettyTable(["车次","出发站","到达站","出发时间","到达时间","历时","特等座","一等座","二等座","软卧","硬卧","软座","硬座","无座"])
for data in res:
list = data.split("|") #分割,获取所有信息填入的list
#print(list)
if list[1]=='列车停运': #根据json 挨个分析
continue
line_no = list[3]
from_sta = list[6]
to_sta = list[7]
start_time = list[8]
stop_time = list[9]
cost_time = list[10]
#字符串 赋值 : or 两个都有值,取第一个,第一个没有值,取第二个
TDZ=list[32] or "--" #特等座
YDZ=list[31] or "--" #一等座
EDZ=list[30] or "--" #二等座
RW=list[23] or "--" #软卧
YW=list[28] or "--" #硬卧
RZ=list[27] or "--" #软座
YZ=list[29] or "--" #硬座
WZ=list[26] or "--" #无座
#表格添加列
table.add_row([line_no, sta_dict[from_sta], sta_dict[to_sta], start_time, stop_time, cost_time, TDZ, YDZ, EDZ, RW, YW, RZ, YZ, WZ])
print (table)
except Exception as e:
print('Error:',e)
为了信息直观方便的输入输出,使用了docopt 和 prettytable两个库。
最终效果如下:
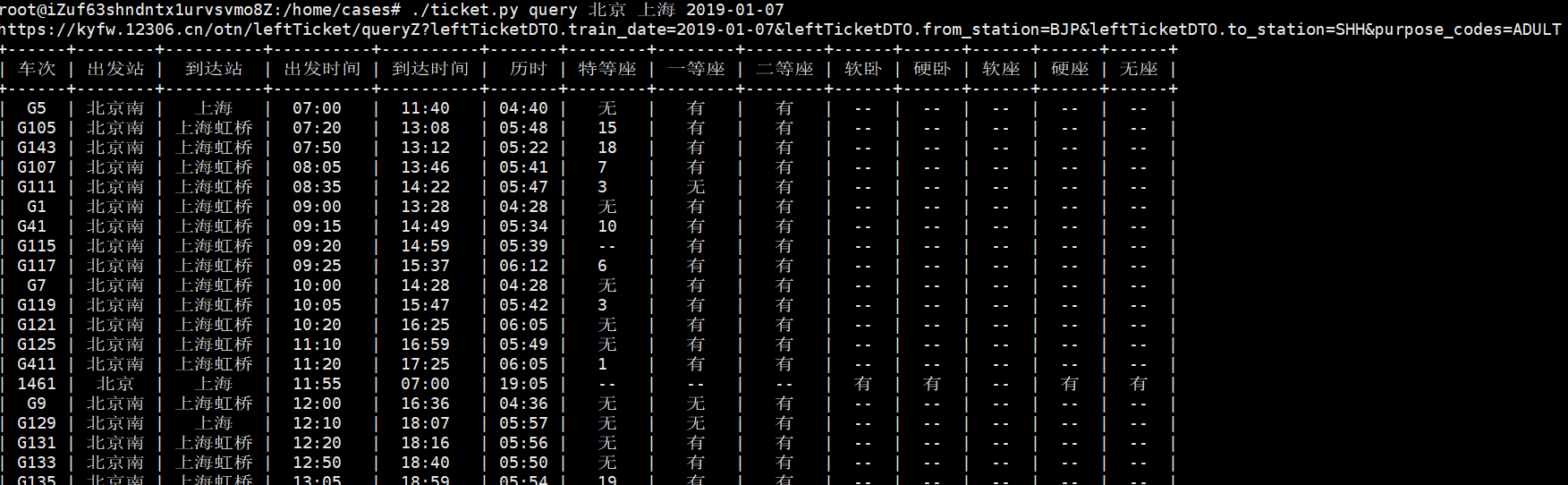
代码上传至GitHub:下载地址 目前是截止2019-1-2测试可用,由于12306网站链接时常更新,可能过后不可用。再改下就好~
原创文章,转载请注明出处:
https://jerrycoding.com/article/12306_ticket_left